
Describe considerations for data ingestion and processing
Data ingestion and processing, two core stages of the data lifecycle, are paramount when orchestrating analytics solutions, especially in cloud ecosystems like Azure. As data flows from its origin to its destination, it often undergoes multiple transformations, making the consid-erations for ingesting and processing crucial for accuracy, efficiency, and scalability. In this extensive overview, we’ll unpack these considerations, delving deeper into the world of data pipelines, transformation mechanisms, and the choices Azure offers.
- Understanding data sources: Every analytics solution starts with understanding where your data originates.
- Type of data: Data can be structured (like SQL databases), semi-structured (like
JSON or XML files), or unstructured (like logs or images). Each type may require dif-ferent ingestion tools and techniques.
- Integration with Azure: Azure provides a plethora of connectors and integration solutions. Azure Synapse, for instance, has connectors for databases, data lakes, on-premises data sources, and many third-party services.
For example, suppose your primary data source is a set of IoT devices. These devices generate high-velocity streaming data, which is often semi-structured.
Figure 4-2 shows some data types.
Skill 4.1 Describe common elements of large-scale analytics CHAPTER 4 107

FIGURE 4-2 Data types
■■ Data volume, velocity, and variety: These three Vs dictate your data strategy.
■■ Volume: This refers to the amount of data you handle. Whether you’re dealing with gigabytes or petabytes will influence your storage and processing choices.
■■ Velocity: This is the rate at which new data is generated and ingested into your sys-tem. This could range from real-time data streams to infrequent batch uploads.
■■ Variety: As previously mentioned, data can come in many formats. The diversity of your data sources can affect your ingestion and processing methods.
■■ Data pipelines, the heart of data movement: In the Azure ecosystem, a data pipeline is the orchestrated flow of data from its source to its destination. Azure Synapse and
Azure Data Factory are the primary services designed for this, allowing you to design and manage these pipelines.
■■ Pipeline activities: These are the actions or “tasks” within a pipeline, like copying data running a data processing activity or executing a data flow.
■■ Triggers: These define the conditions under which a pipeline runs. They could be scheduled or event-driven.
For example, a retail company might set up a pipeline in Azure Data Factory or Azure Synapse to ingest sales data at the end of every business day, transforming and aggregating this data for daily sales reports. Figure 4-3 depicts the Azure Data
Factory Pipeline workflow.
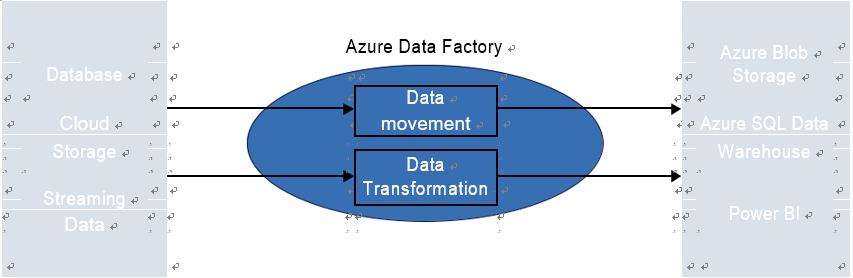
| FIGURE 4-3 Azure Data Factory Pipeline workflow |
■■ Transformations such as ETL versus ELT: Depending on when you transform your data (before or after loading it into your analytical store), you might be working with extract, transform, load (ETL) or extract, load, transform (ELT). See Figure 4-4.
■■ ETL: ETL is best when raw data needs cleaning or transformation before it’s suitable for analytical processing.
■■ ELT: ELT is suitable when the analytical data store in powerful enough to handle transformations. Azure’s Synapse Analytics (formerly SQL Data Warehouse) is designed for this approach.
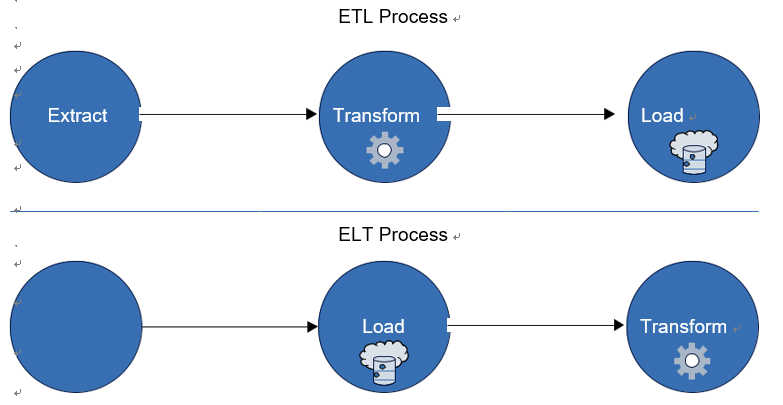
FIGURE 4-4 ETL versus ELT
■■ Security, compliance, and data governance: Azure provides a comprehensive suite of tools and best practices to ensure your data is secure and compliant.
■■ Encryption: Always ensure data is encrypted both in transit and at rest. Services like Azure Blob Storage provide automatic encryption.
■■ Access control: Use Azure Active Directory for identity services and role-based access control.
■■ Auditing and monitoring: Regularly monitor data operations using tools like Azure Monitor and Log Analytics.
■■ Scalability, reliability, and cost management: Azure’s cloud-based model allows for immense scalability, but it’s essential to manage resources effectively.
■■ Scaling: Use services that allow both vertical and horizontal scaling. Azure Cosmos DB, for instance, provides global distribution and elastic scaling of throughput.
■■ Reliability: Ensure your services have redundancy and backup capabilities. Azure’s geo-redundant storage (GRS) is a good example of a service that provides auto-mated backups in multiple locations.
■■ Cost management: Monitor and analyze your Azure spending with tools such as Azure Cost Management and Azure Advisor.
Skill 4.1 Describe common elements of large-scale analytics CHAPTER 4 109
As you venture deeper into Azure’s world of data ingestion and processing, it’s paramount to approach the subject with a holistic view. By focusing on these critical considerations, you’ll ensure that your data solutions are not only efficient but also secure, scalable, and cost-effective.
Leave a Reply